前言
Deep Residual Learning for Image Recognition
ResNet是何凯明(微软亚洲AI研究院工作)提出的残差神经网络,曾经在Kaggle等平台上获得多次大奖。
为什么提出ResNet
众所周知,随着神经网络的发展,深度越大,网络的表达性能就越好,可实际训练的时候,随着深度的加大,网络出现了梯度弥散(也有叫梯度消失等)的情况。
比如说在原始的网络当中,输入变量每经过一层就通过一次sigmoid激活函数,由于sigmoid函数只在0附近梯度变化明显,远离0附近梯度变化趋近于0,因此随着网络的深化,梯度变化趋于0,相当于线性恒等映射,深化的网络是做了无用功。
为了解决该问题,人们想了一些办法,比如说改变激活函数使用relu,Leaky—relu,或者Batch Normalization等,但是不能从根本上解决问题,因此何凯明提出了ResNet(残差神经网络)
其他参考
虽然通过Batch Normalization或者正则初始化等能够训练了,但是又会出现另一个问题,就是退化问题,网络层数增加,但是在训练集上的准确率却饱和甚至下降了。
退化问题说明了深度网络不能很简单地被很好地优化
ResNet是什么?怎么解决梯度弥散以及退化问题?
两种mapping
何凯明在ResNet中提出两种mapping:
- identity mapping(处理图像中也称叫feature map):就是本身,即下图中的x
- residual mapping:指的公式中的$F(x)$
残差函数
ResNet中通过学习残差函数来解决问题,学习差值比学习梯度变化要容易的多,摘录知乎解释:F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F’(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F’和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如s输出从5.1变到5.2,映射F’的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化,看到残差网络我第一反应就是差分放大器…(博主:哈哈,刚开始接触ResNet的时候我还没学到差分放大器)
上述中的$H(x)=F(x)+x$,$F(x)$为残差函数,如果$F(x)=0$,则为恒等映射,这样设计网络可以保证随着深度的加大,不论怎么训练,至少层数更深的网络训练的效果不会比层数浅的网络效果差,网络会一直处于最优状态(理论上),且残差拟合更加容易,学习速度更快。
Residual Block

上图为Residual Block,可以看到输入变量x,通过两层网络和x(通过shortcut)进行element-wise add(就是对应元素加到一起,element-wise是对应元素相乘),然后再经过一个relu输出就是一个Residual Block。

这两种结构常用在ResNet18,ResNet34(左图),ResNet50/101/152(右图),其中右图又被称作”bottleneck”
ResNet-18 Cifar-10
Cifar-10
这个数据集包含60000张32*32的彩色图片,这些图片一共被分成10类,有小猫,小狗等……详见:https://www.cs.toronto.edu/~kriz/cifar.html
ResNet-18网络结构
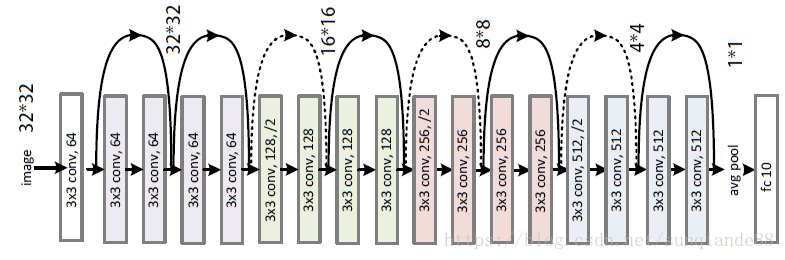
上图中虚线表示channel改变,实线表示channel不变
实现代码1
1 | import torch |
小结
- 该代码没有完整实现ResNet-18结构,只实现了两residual Block。后面我自己会补上
- 初学ResNet,这个代码还是很OK的。
实现代码2
注:这段代码摘录于CSDN,由作者所说,acc = 95.170%,是完整实现ResNet-18,且封装性优于上述代码,参考价值很高
Pytorch上搭建ResNet-18:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70'''ResNet-18 Image classfication for cifar-10 with PyTorch
Author 'Sun-qian'.
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class ResidualBlock(nn.Module):
def __init__(self, inchannel, outchannel, stride=1):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
def forward(self, x):
out = self.left(x)
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, ResidualBlock, num_classes=10):
super(ResNet, self).__init__()
self.inchannel = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.layer1 = self.make_layer(ResidualBlock, 64, 2, stride=1)
self.layer2 = self.make_layer(ResidualBlock, 128, 2, stride=2)
self.layer3 = self.make_layer(ResidualBlock, 256, 2, stride=2)
self.layer4 = self.make_layer(ResidualBlock, 512, 2, stride=2)
self.fc = nn.Linear(512, num_classes)
def make_layer(self, block, channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1) #strides=[1,1]
layers = []
for stride in strides:
layers.append(block(self.inchannel, channels, stride))
self.inchannel = channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
def ResNet18():
return ResNet(ResidualBlock)Pytorch上训练:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import argparse
from resnet import ResNet18
import os
# 定义是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 参数设置,使得我们能够手动输入命令行参数,就是让风格变得和Linux命令行差不多
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--outf', default='./model/', help='folder to output images and model checkpoints') #输出结果保存路径
args = parser.parse_args()
# 超参数设置
EPOCH = 135 #遍历数据集次数
pre_epoch = 0 # 定义已经遍历数据集的次数
BATCH_SIZE = 128 #批处理尺寸(batch_size)
LR = 0.01 #学习率
# 准备数据集并预处理
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), #先四周填充0,在吧图像随机裁剪成32*32
transforms.RandomHorizontalFlip(), #图像一半的概率翻转,一半的概率不翻转
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), #R,G,B每层的归一化用到的均值和方差
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train) #训练数据集
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2) #生成一个个batch进行批训练,组成batch的时候顺序打乱取
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
# Cifar-10的标签
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 模型定义-ResNet
net = ResNet18().to(device)
# 定义损失函数和优化方式
criterion = nn.CrossEntropyLoss() #损失函数为交叉熵,多用于多分类问题
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4) #优化方式为mini-batch momentum-SGD,并采用L2正则化(权重衰减)
# 训练
if __name__ == "__main__":
if not os.path.exists(args.outf):
os.makedirs(args.outf)
best_acc = 85 #2 初始化best test accuracy
print("Start Training, Resnet-18!") # 定义遍历数据集的次数
with open("acc.txt", "w") as f:
with open("log.txt", "w")as f2:
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
correct = 0.0
total = 0.0
for i, data in enumerate(trainloader, 0):
# 准备数据
length = len(trainloader)
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
# forward + backward
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 每训练1个batch打印一次loss和准确率
sum_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('%03d %05d |Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('\n')
f2.flush()
# 每训练完一个epoch测试一下准确率
print("Waiting Test!")
with torch.no_grad():
correct = 0
total = 0
for data in testloader:
net.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
# 取得分最高的那个类 (outputs.data的索引号)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('测试分类准确率为:%.3f%%' % (100 * correct / total))
acc = 100. * correct / total
# 将每次测试结果实时写入acc.txt文件中
print('Saving model......')
torch.save(net.state_dict(), '%s/net_%03d.pth' % (args.outf, epoch + 1))
f.write("EPOCH=%03d,Accuracy= %.3f%%" % (epoch + 1, acc))
f.write('\n')
f.flush()
# 记录最佳测试分类准确率并写入best_acc.txt文件中
if acc > best_acc:
f3 = open("best_acc.txt", "w")
f3.write("EPOCH=%d,best_acc= %.3f%%" % (epoch + 1, acc))
f3.close()
best_acc = acc
print("Training Finished, TotalEPOCH=%d" % EPOCH)实现效果
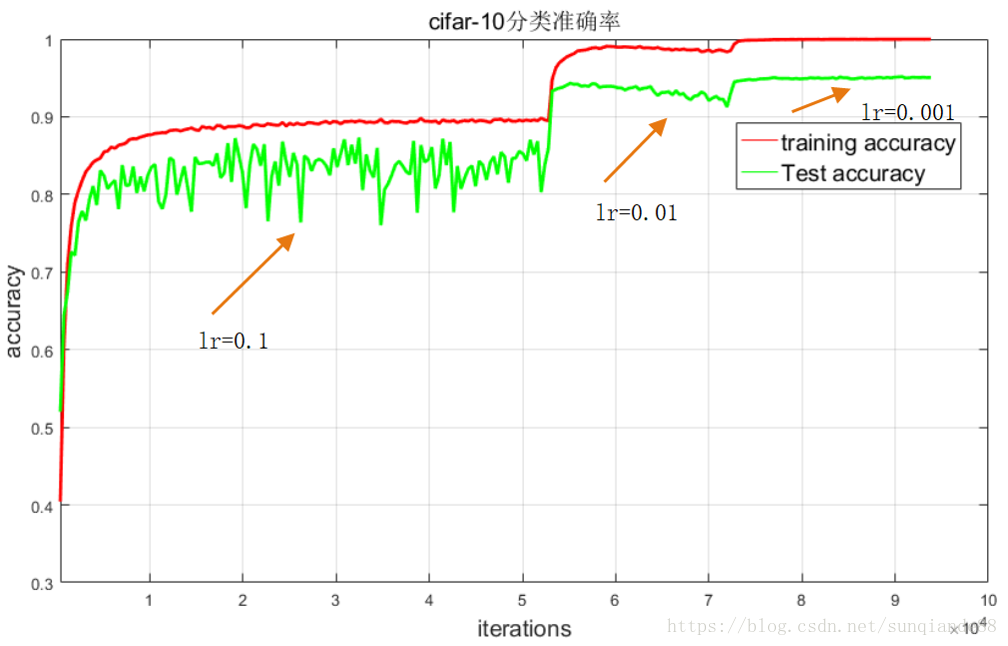
注:该图像是作者将数据下载到.txt文件,然后再matlab中进行生成
小结
- 将数据导入.txt文件,用matlab处理
确实是好方法,visdom用起来也会很方便
- 定义GPU是否使用的写法
- ResNet-18模块封装性很好,完全符合结构
困惑
在make_layer那里最后一句的return nn.Sequential(layers)中的layers是什么意思呢,上面加*是什么意思呢?参考文献
- https://blog.csdn.net/sunqiande88/article/details/80100891
- http://www.jeepxie.net/article/601129.html
- https://www.jianshu.com/p/e58437f39f65
- https://www.zhihu.com/question/53224378/answer/159102095
- Cifar-10:https://www.cs.toronto.edu/~kriz/cifar.html

